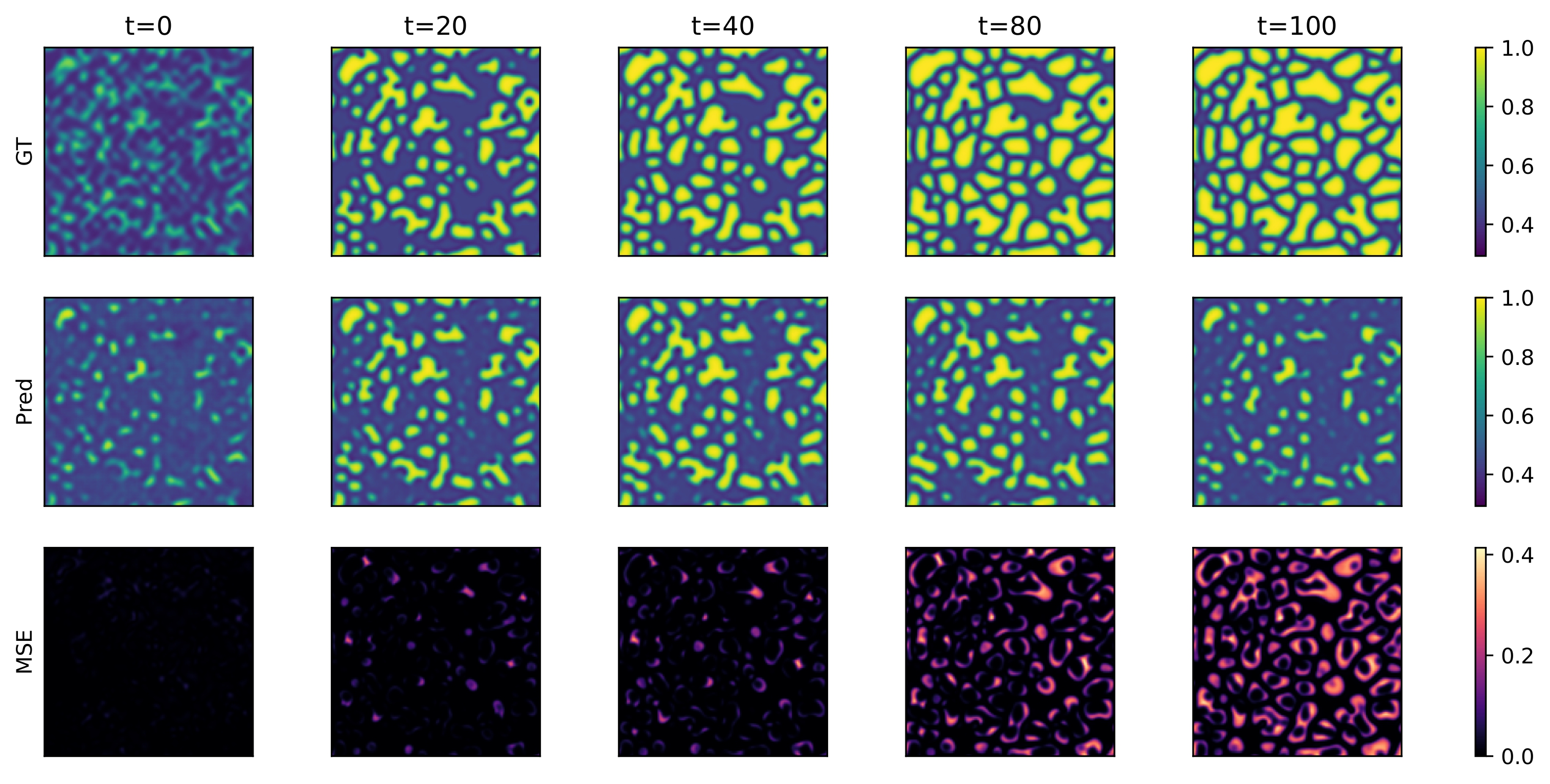
The ECHO framework
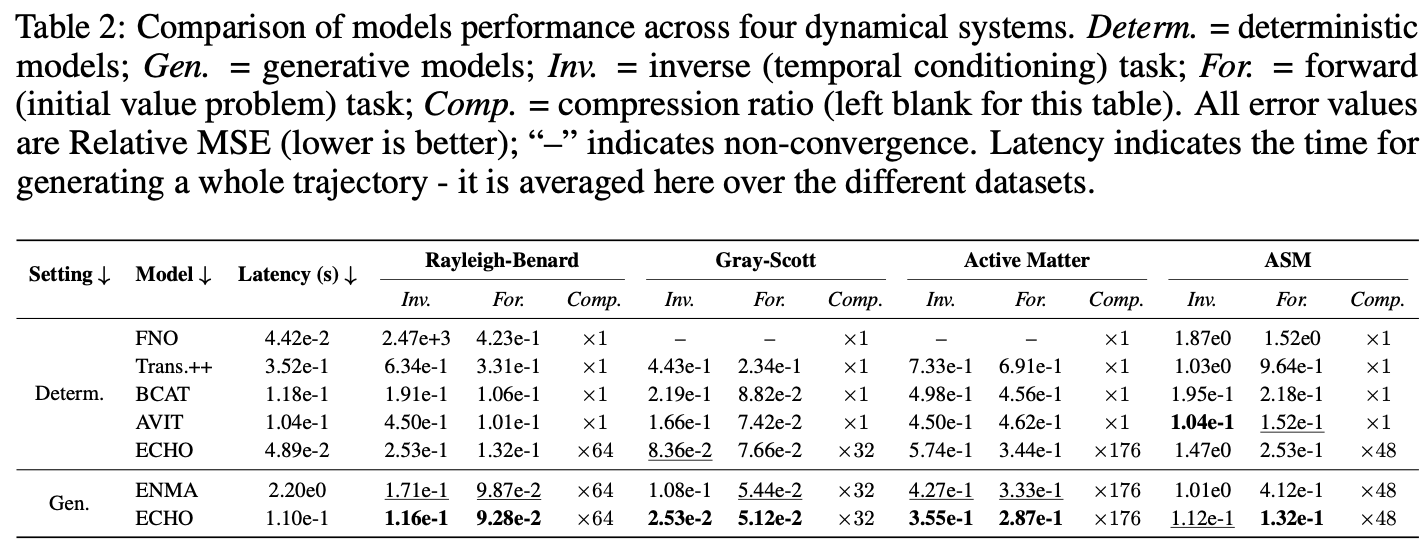
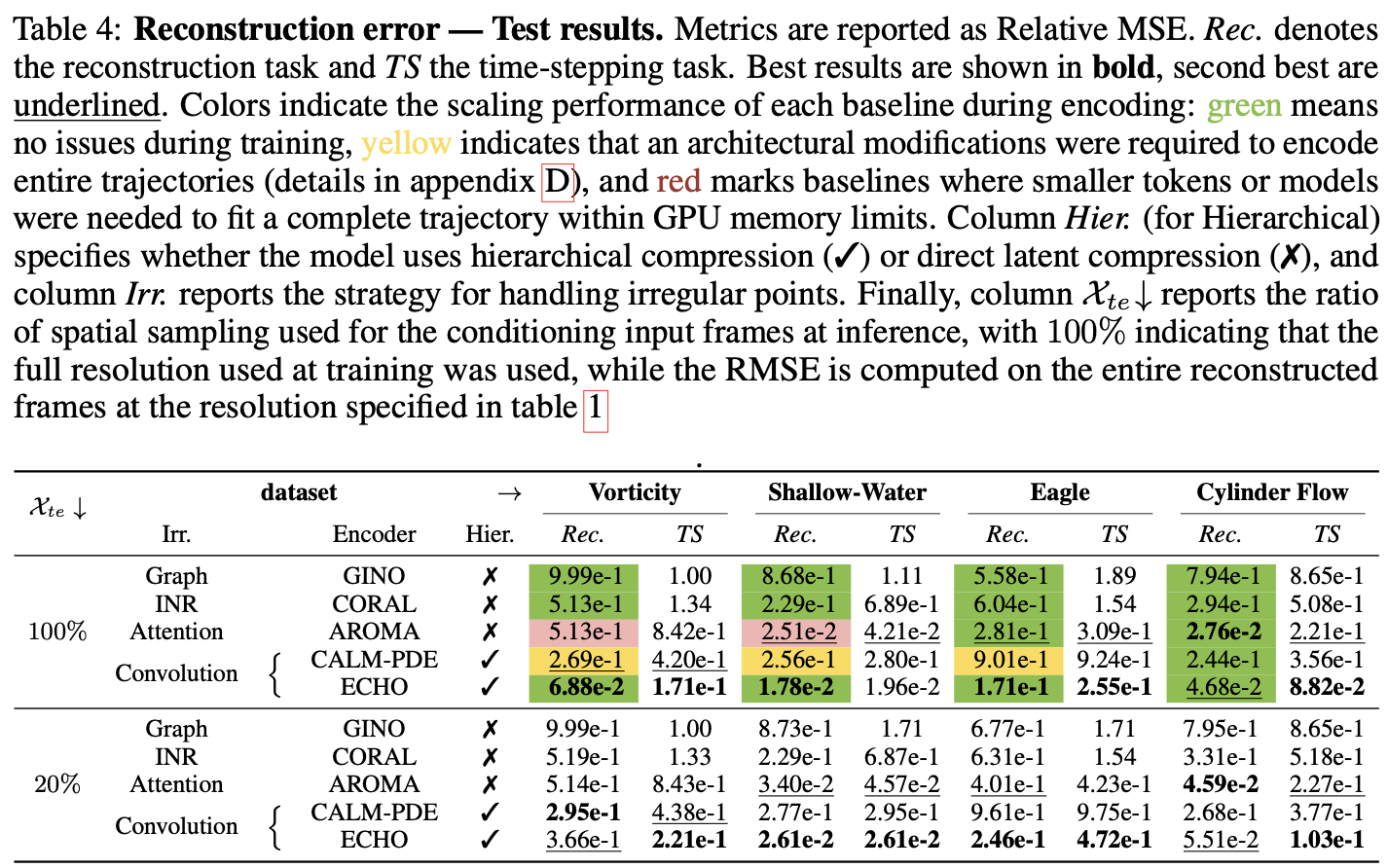
ECHO is a transformer-based operator built on an encode–generate–decode framework designed for efficient spatio-temporal PDE modeling at scale. It allows us to handle million-point trajectories on arbitrary domains (see Figure bellow). ECHO is the first generative transformer operator addressing under a unified formalism forward and inverse tasks, while operating in a compressed latent space, allowing scaling to high-resolution inputs from arbitrary domains.
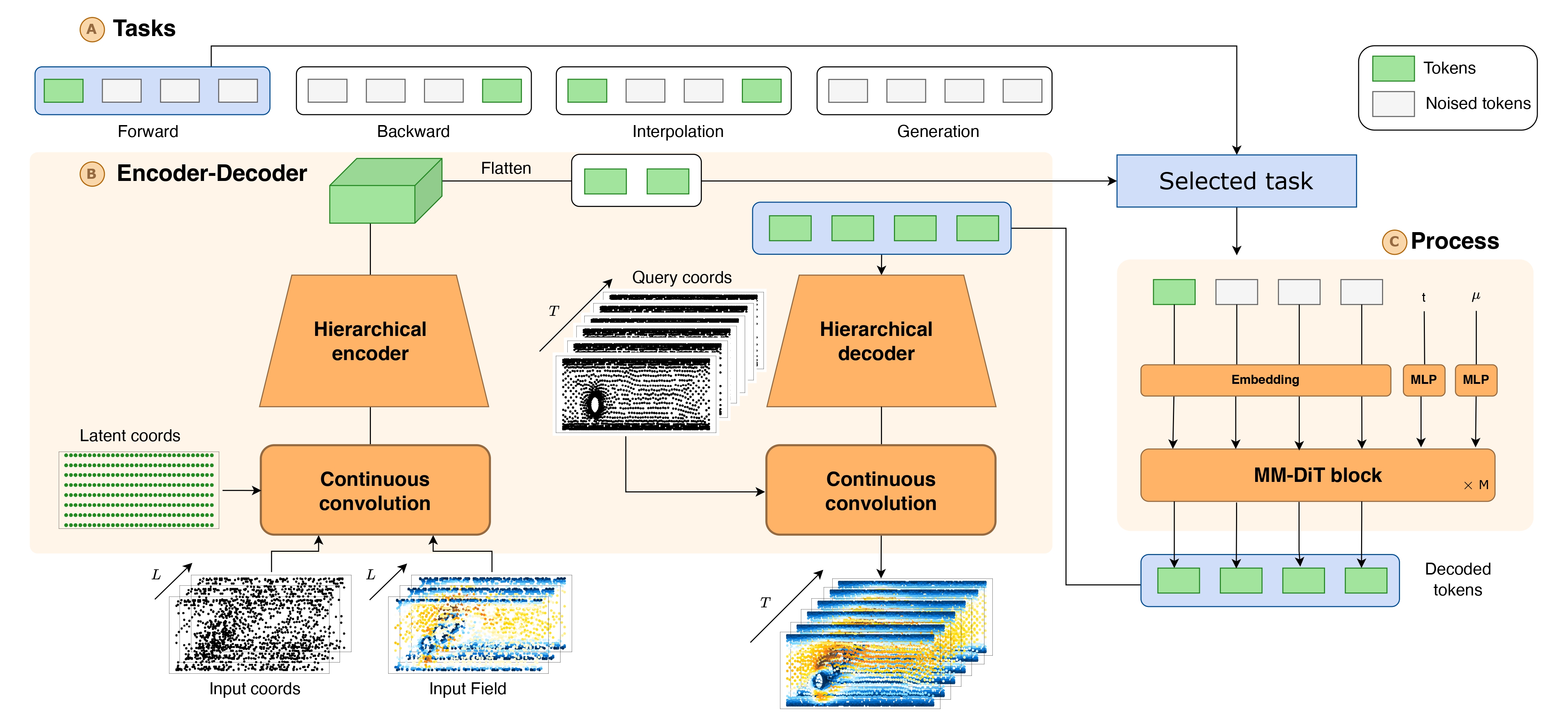
The design of our model ECHO, follow 3 keys principles:
- (i) Hierarchical spatio-temporal compression: For realistic deployment, compression must act jointly on space and time. We advocate deep encoder–decoders that reduce resolution hierarchically, yielding compact yet faithful spatio-temporal latents.
- (ii) Rethinking the auto-regressive process: Next-frame(s) prediction remains the dominant training paradigm for the process, while suffering from error drifts. We introduce a robust procedure that generates entire trajectory segments conditioned on selected frames. It captures long-range temporal dependencies and enforces horizon-wide consistency.
- (iii) deterministic to generative modeling: we leverage a stochastic modeling formulation for generating trajectory distributions. This allows us to deal with partial or noisy observations, and to cope with the physical information loss inherent to the compression step.
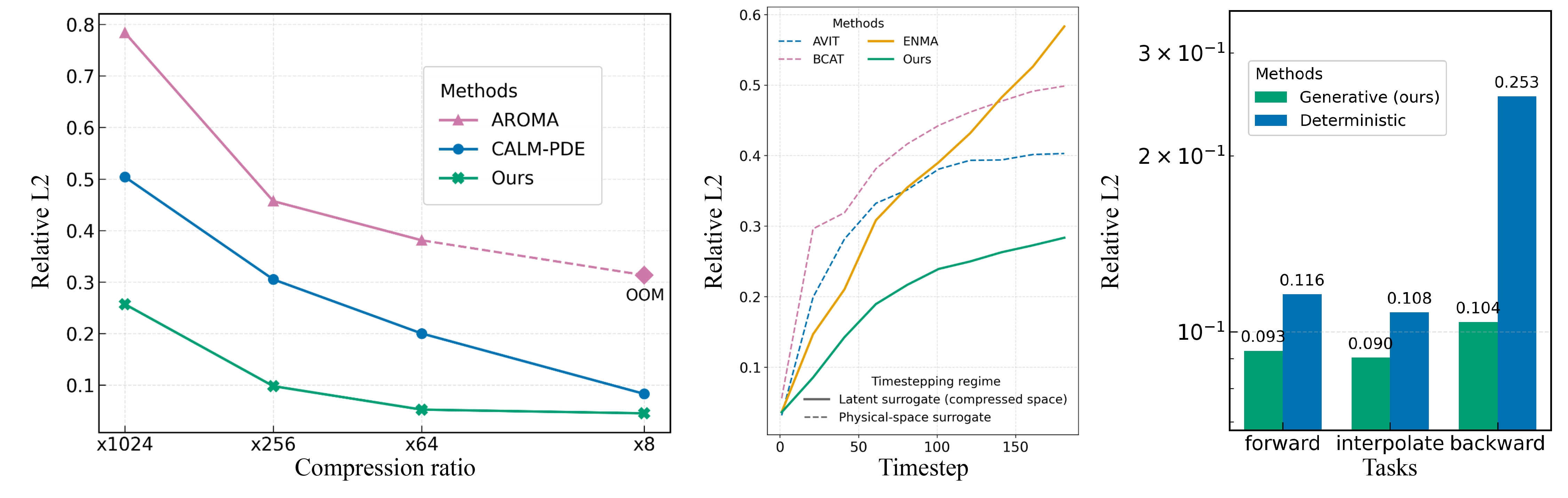
The figure below illustrates the benefits of principles (i)–(iii): (left) our spatio-temporal encoder achieves a compression ratio versus relative L2 error that is markedly superior to state-of-the-art baselines enabling large scale applications; (center) its trajectory-generation procedure is far less prone to error accumulation, enabling long-horizon forecasts; and (right) the generative modeling paradigm outperforms deterministic alternatives.